
The AI transformation narrative is compelling but look behind the curtain at any enterprise deployment, and you will almost certainly find a retrieval pipeline quietly doing the heavy lifting. Define with us RAGOps, why it matters, and what the smartest organizations are building right now.
There is a gap between what enterprise AI looks like in a press release and what it looks like in a production environment. The press release version involves a company “deploying large language models to transform operations.” The production version, in most cases, involves a retrieval system that fetches relevant documents, injects them into a prompt, and lets the model synthesize an answer. That mechanism has a name: Retrieval-Augmented Generation, or RAG. The operational practices that keep RAG running well have a newer, increasingly important definition with RAGOps.

RAG is the right approach for most enterprise use cases as it keeps AI outputs grounded in real, current, proprietary data rather than relying on a frozen snapshot of the world from a model training run. It mitigates hallucinations, enables compliance, and makes AI legible to the people responsible for governing it. The challenge is that most organizations treat RAG as a build-and-forget engineering project rather than a continuous operational discipline — and that gap is where things quietly fall apart.
What RAG Actually Is
The obsolete LLMs, by itself, only know what they learned during training and fine-tuning stages. Feed a question about your company’s Q1 2026 earnings or your internal compliance policy updated last Thursday, and it will either hallucinate an answer or confess ignorance. RAG solves this by giving the model a secure retrieval stage before it generates the output. When a user submits a query, the system searches for a curated data store; typically, a vector database to pull out the most semantically relevant documents, and passes that retrieved context to the model as part of the prompt. The model reasons for real, current information rather than stale parametric memory.
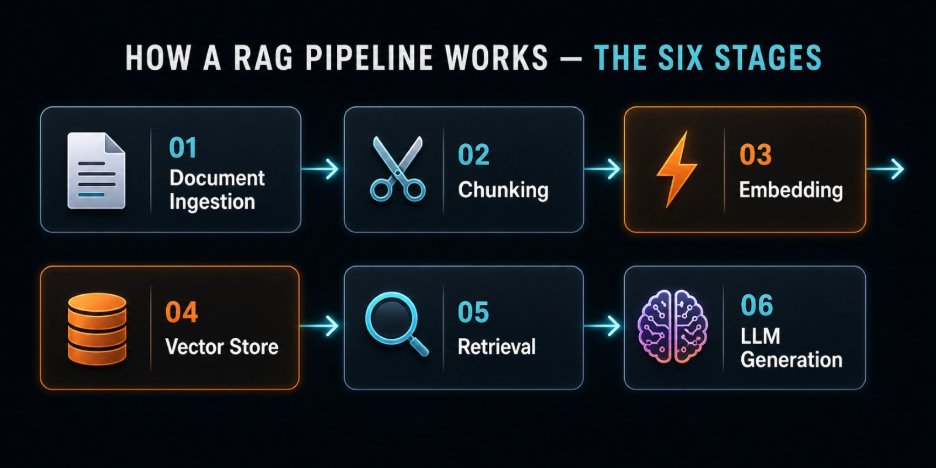
The reason RAG became the default architecture for enterprise AI is practical; giving developers valuable operational flexibility at enterprise scale. Fine-tuning a model on proprietary data is expensive, slow, and requires retraining every time the underlying data changes. RAG solves the same problem by keeping the retrieval layer dynamic and the model layer stable. Usually upon a policy change or a new launch in your product mix, you update the knowledge base and retrieval logic rather than retrain the model.
RAGOps: The Requisite Discipline Making LLMs Market-Ready
RAGOps is the end-to-end lifecycle management of RAG layer, spanning data preprocessing, orchestration, vector storage, and continuous evaluation of the layer mechanics and output generated.
RAGOps defines a conceptual framework as MLOps evolves with a focused emphasis on data lifecycle management and settlement on data used to generate answers. Where LLMOps handles model versioning, prompt management, and deployment pipelines, RAGOps govern the indexing, parse, extraction of continuously changing external data that retrieval systems depend on. That distinction matters enormously in practice, because retrieval quality decays over time as data grows stale; collections expand without proper documentation, or user query patterns are not fully considered.
For instance, a company spends three months building a RAG pipeline for its internal knowledge base and worked well during the initial period but six months later, the retrieval is surfacing outdated product specs, the chunking strategy that worked for short policy documents is breaking on newly ingested technical reports, and information silos are built between individual departments. You surely cannot rely on the answers the models are generating at this stage. Here we have experienced failure of RAGOps. The model did not get worse; the operational infrastructure was not resilient to survive because nobody was treating retrieval as a production system requiring oversight and continuity.
| Analyst Insight |
| Recent 2026 enterprise AI studies indicate that retrieval-augmented generation (RAG) has become the dominant architecture for production LLM systems, with many organizations now rebuilding their stacks around hybrid and agentic retrieval approaches. As of today, industry research reports many organizations still lack dedicated monitoring for retrieval relevance – embedding quality, grounding fidelity, and answer drift; this means a large share of enterprise AI systems continue to operate with limited observability into their most failure-prone layer. |
The Evolution Beyond Naive RAG
Analysts and developers must understand these distinct types of RAGs when evaluating enterprise AI capabilities. Simplistic pipelines are rarely enough for real-world complexity and speed. Organizations need modular, dynamic, and intelligent architecture that fulfils enterprise operational and management needs.
| RAG Type | Core Capability | Typical Enterprise Use Case |
| Naive RAG | Retrieves documents and passes them directly to the LLM | Prototypes, internal copilots, lightweight knowledge search |
| Rerank RAG | Reorders retrieved results using relevance scoring models | Improves retrieval precision and reduces hallucinations |
| Multimodal RAG | Retrieves and reasons over text, images, audio, or video | Document intelligence, healthcare imaging, media analysis |
| Graph RAG | Uses structured entity relationships and knowledge graphs | Explainability, compliance, enterprise knowledge management |
| Hybrid RAG | Combines vector, keyword, metadata, or graph-based retrieval | Balances recall, precision, and robustness in production systems |
| Agentic RAG | Dynamically selects tools, retrieval paths, or workflows | Complex enterprise workflows and real-time decision support |
| Multi-Agent RAG | Multiple AI agents collaborate on retrieval and reasoning | Cross-functional automation and distributed task orchestration |
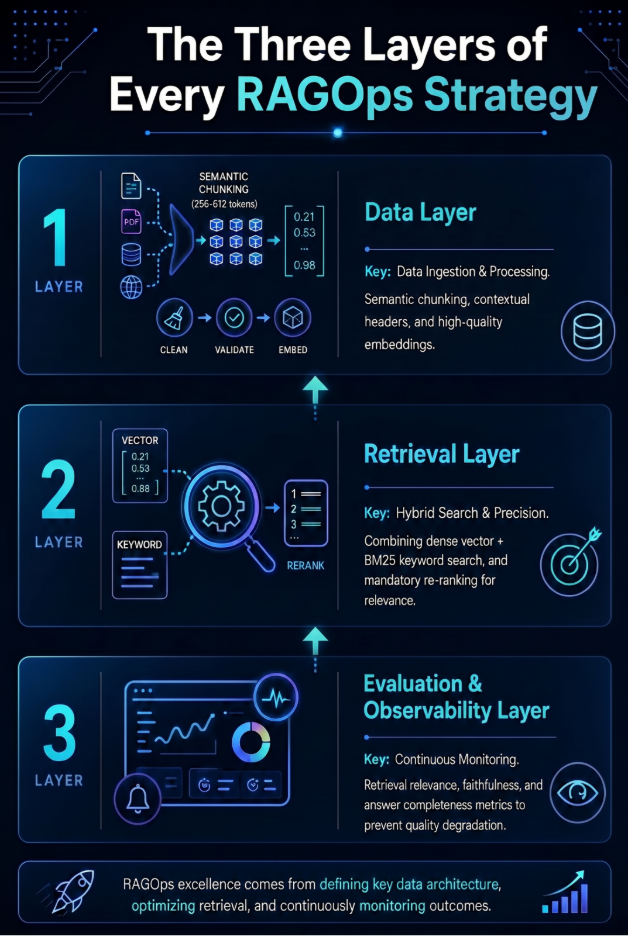
The Three Layers Every RAGOps Strategy Must Address
A mature RAGOps practice operates across three distinct layers that map directly to where enterprise AI deployments tend to succeed or fail. Understanding these layers is the first step toward building AI infrastructure that holds up beyond the pilot stage.
The Tool Stack That Is Winning in 2026
The enterprise RAG tooling landscape has matured into three functional tiers: orchestration frameworks, vector databases, and managed RAG-as-a-service platforms. Each serves a different organizational profile depending on technical depth, budget, and time-to-value requirements.
LangChain
Orchestration Framework
The go-to for rapid prototyping with 50,000+ integrations. Version 0.2.7 introduced LangGraph for complex multi-step reasoning and LangSmith for production-grade observability and tracing.
LlamaIndex
Document-Centric RAG
Achieved a 35% boost in retrieval accuracy by 2025 and remains the preferred choice for document-heavy applications like legal research, technical documentation, and compliance workflows.
Pinecone / Weaviate
Vector Databases
Pinecone leads in managed cloud deployments; Weaviate offers self-hosting flexibility and strong enterprise governance. Both serve as the retrieval backbone that AI framework sits on top of.
Haystack
Production Pipelines
Built for production from the ground up. Its explicitly modular pipeline architecture makes every retrieval step inspectable — particularly valuable for regulated industries requiring auditability.
Vectara / Ragie
Manage RAG As A Service
Bundle ingestion, embedding, retrieval, and generation into a single API. Best for organizations that need the fastest time-to-value and are willing to trade pipeline flexibility for reduced engineering overhead.
AWS Bedrock KB / Azure AI Search
Cloud Native Options
Zero-ops deployment within existing cloud ecosystems. The path of least resistance for organizations already deeply committed to a cloud provider’s broader AI and data infrastructure.
A Practical RAGOps Checklist for Enterprise Teams
Organizations that are successfully operationalizing RAG share a set of consistent practices. The following are not aspirational best practices — they are the observable differences between pilots that scale and pilots that stall.
✓ Treat the knowledge base as a product. It has owners, updates, quality standards, and a deprecation policy. Documents that are stale or out of scope should be separated from the pipelines.
✓ The model’s output can sound confident even when the retrieved context is poor. Continuously measure relevance, context recall, and faithfulness as distinct, automated metrics in production.
✓ Implement hybrid retrieval from the start. Dense-only or sparse-only retrieval is a technical debt decision. Hybrid retrieval with re-ranking is not significantly harder to implement and delivers materially better results on real enterprise datasets.
✓ Version your pipelines like code. Chunking strategies, embedding models, retrieval parameters, and prompt templates should all be tracked and versioned. This makes debugging straightforward and enables rollbacks when a change degrades quality.
✓ Budget for cost of monitoring infrastructure. Automated evaluation using a secondary LLM as a coordinator; this practice now mainstreams in production RAG that requires deliberate investment in prompt design, scoring rubrics, and continuous review cycles. It is not free, but the cost of implementing RAG is lower than failures and legal breaches.
Industry Applications: Where RAG Is Creating Real Value
Public examples prove these architectures are moving into operational workflows rather than experimental pilots and increasing market competitiveness of foundational models and AI platform or service providers. Microsoft has expanded retrieval-grounded copilots across enterprise productivity and security platforms, combining orchestration agents with enterprise knowledge retrieval to support workflow automation and contextual reasoning. NVIDIA and ServiceNow have also demonstrated agentic enterprise AI systems that coordinate multiple retrieval and reasoning agents for IT operations, customer support, and enterprise workflow management. In healthcare and life sciences, organizations are deploying multimodal RAG systems capable of retrieving and reasoning across clinical notes, research papers, imaging data, and structured medical records.
The reason is not necessarily greater technical sophistication, but greater sensitivity to factual accuracy, traceability, and compliance. In these environments, hallucinated outputs can create regulatory, legal, financial, or reputational risk, making retrieval grounding a core architectural requirement rather than an optional enhancement.
By 2026, enterprise deployments have also evolved beyond basic vector search pipelines toward more advanced forms of Hybrid RAG, Graph RAG, and Agentic RAG. AI architecture combines dense vector retrieval with keyword search, metadata filtering, knowledge graphs, and tool-aware orchestration to improve reliability in production systems.
From Retrieval to Context Engine: What Comes Next
Today, leading practitioners are describing modern AI infrastructure as context engine, a system whose primary contribution is not generation but intelligent, dynamic grounding of every AI interaction in verified, current, proprietary knowledge. The retrieval layer is growing smarter: self-querying systems now automatically evaluate and reformulate search queries mid-flight to improve relevance. Multimodal retrieval pipelines extend the paradigm beyond text to images, audio, tabular data, and video. Many enterprises are no longer building retrieval into individual applications but establishing it as shared infrastructure with a context layer that sits beneath their entire AI stack and serves every model, agent, and workflow from a single authoritative source.
The competitive divergence that RAGOps creates is becoming visible in performance data. Organizations that have built disciplined retrieval infrastructure report faster time-to-insight, higher user trust in AI outputs, lower hallucination rates, and cleaner paths to compliance. Those that have not been discovered that a capable language model sitting on top of a poorly maintained knowledge base is not a competitive asset, but it is a liability that produces confident errors at scale. The model does not know what it does not know.
Stop thinking of your retrieval infrastructure as an engineering detail inside an AI project and start thinking of it as core data infrastructure on par with your data warehouse or your CRM. It requires the same governance, the same operational rigor, and the same dedicated ownership as your business technology foundations.

