
The architectural decisions separating production-ready AI systems from expensive demos have become clearer in 2026. This article examines seven foundational principles shaping agentic AI development this year, drawing on insights from leading engineers and researchers whose systems were built on these patterns to prevent failures, reduce costs, and deliver dependable AI performance at scale.
By late 2025, agent behavior had grown safer, more suited to complex workflows, and markedly more coherent in its outputs. After two years of scrutinizing every tool-calling loop, engineers began extending genuine trust to agents as production subsystems capable of completing tasks reliably. At Sequoia’s AI Ascent conference in April 2026, Andrej Karpathy, now a member of Anthropic’s pre-training team, described a milestone that marked a clear boundary: Claude Code and OpenAI Codex had moved beyond requiring constant correction to earning trust within extended workflows. The unit of programming moved from auto-correcting individual lines of code to orchestrating macro-level actions. Developers can now implement new AI features fluidly, experiment with upgrades without friction, refactor subsystems, write tests on demand, and trace the root cause of failures.

By early 2026, the most consequential production failures had no meaningful connection to the quality of the underlying language models. They were architectural failures: agents looping on recoverable errors because no critic layer existed to interrupt them; multi-agent pipelines where a single malformed tool call corrupted every downstream step; memory systems that stored stale information yet retrieved it with unwarranted confidence. Datadog’s 2026 State of AI Engineering report found that 69 percent of LLM input tokens in deployed agentic systems were system prompt tokens, a revealing proxy for how much engineering effort was being spent patching architectural weaknesses through prompting rather than resolving them structurally. No amount of prompt engineering substitutes for a missing evaluation layer.
More than 50 percent of companies are now deploying agents for multi-stage workflows, according to the Anthropic 2026 State of AI Agents Report. Several analyst assessments of enterprise AI development in 2025 and 2026 estimated that more than 80 percent of AI projects never reached production. The seven patterns described here represent what bridges that gap. Each maps to a concrete failure mode that can be identified, diagnosed, and resolved.
Why a Single Agent Is Not Enough
A single generalist agent for handling planning, execution, memory access, tool calls, error recovery, and output validation can work for simple, linear tasks. The problems surface as context windows grows, tasks become more demanding, reasoning quality becomes critical to outcomes, and errors accumulate without any path to recovery. According to the LangChain 2026 State of AI Agent Engineering Report, output quality is the primary deployment blocker, cited by 32 percent of practitioners, with latency ranking second at 20 percent. A monolithic agent’s performance degrades sharply when a task requires it to hold contradictory roles simultaneously.
Harrison Chase, CEO and co-founder of LangChain, whose platform has surpassed one billion downloads, framed the issue precisely at LangChain’s Interrupt 2026 conference: “When agents mess up, they mess up because they don’t have the right context. When they succeed, they succeed because they have the right context. The biggest differentiator for production agents is not the underlying model; it’s the infrastructure surrounding it.” High-performing agents are not simply powered by capable models. They are built on the right architectural patterns.
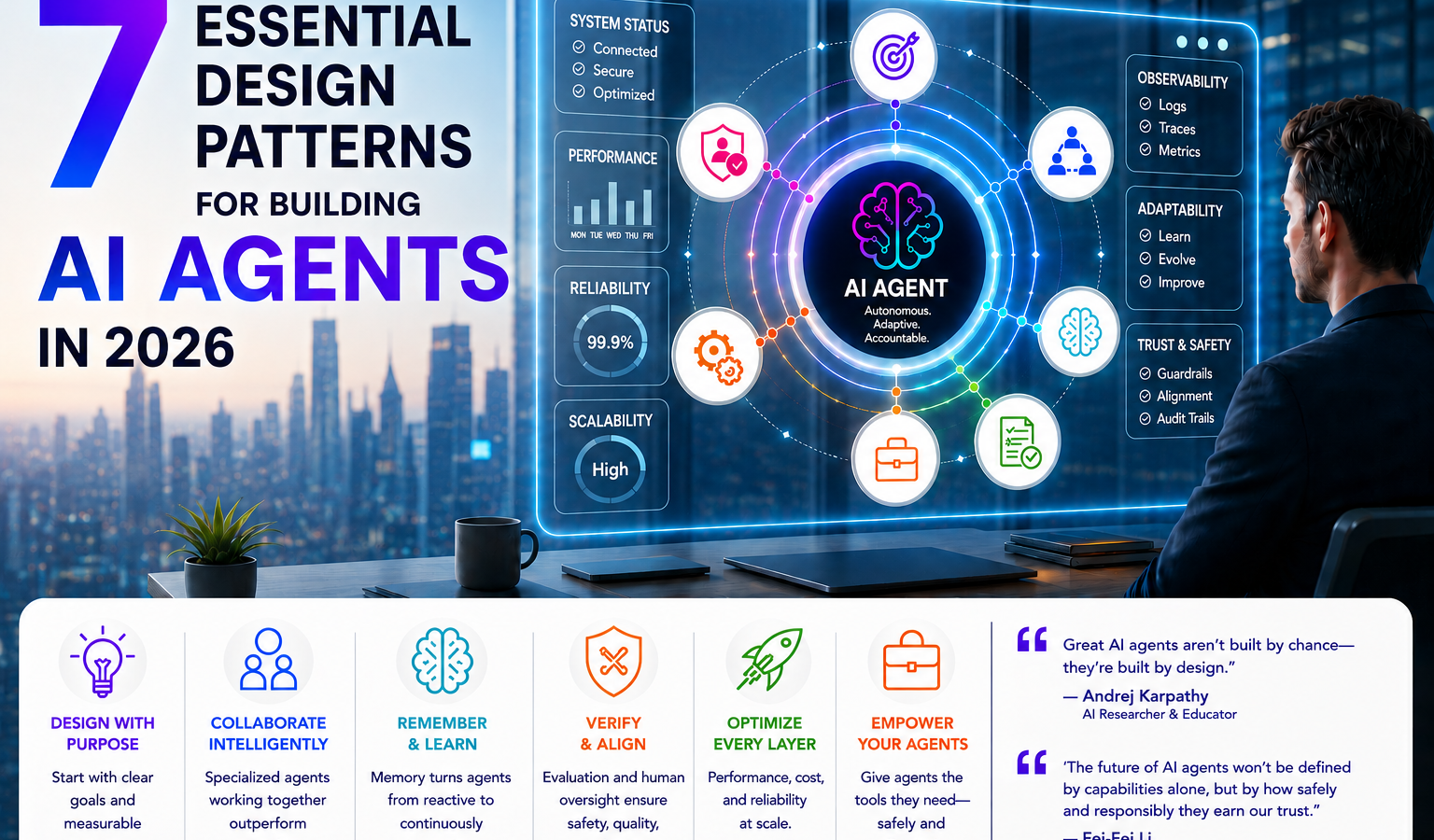
7 Patterns You Need For Your AI Agents

1. Plan-and-Execute Patterns and Goal-Oriented Architecture
The ReAct pattern (Reason-Act) alternates between generating thoughts, taking actions, and observing results. It works well for exploratory tasks where the next correct step depends on what the previous one revealed. For long-form, structured tasks, however, that improvisational quality becomes a liability: an agent may commit to a flawed step of ten iterations before recognizing the error. The Plan-and-Execute approach addresses this directly.
A dedicated planning model produces a complete multi-step plan upfront. A separate executor, typically a faster and less expensive model, then carries out each step without re-evaluating the overall strategy. Where subtasks are independent, they can run in parallel, much like querying three databases simultaneously rather than sequentially. For complex workflows, this cuts wall-clock time by roughly 50 percent.
Goal-Oriented Architecture extends this further by defining a measurable end state before execution begins. The agent works backward to construct the required steps, continuously references the goal throughout execution, and uses it as the criterion for validating individual subtasks. The Agent Runtime announced at Google Cloud Next ’26 can sustain agent state for up to seven days, a direct acknowledgment that real production tasks cannot fit within a single session.
Plan-and-Execute architectures achieve task success rates of up to 92 percent and can run up to 3.6 times faster than linearly executing ReAct architectures, according to 2026 benchmarks published by LangChain and n1n AI. When independent subtasks run in parallel, those figures improve further.
Production Tip
Build scope clarification into the planner. An agent given an ambiguous task without defined primary objectives will execute with confidence in the wrong direction.
2. Multi-Agent Coordination and the Orchestrating Crew
The transition from monolithic applications to microservices in software engineering has a direct parallel in AI agent design. Distributing work across specialized agents enables simpler individual prompts, genuine parallelization, and the flexibility to assign different models to different roles within the same system. Two coordination patterns are becoming production standards.
The Orchestrator model assigns a single orchestrator agent responsibility for the goal. It decomposes the problem into discrete tasks, dispatches them to specialized agents, and synthesizes the results. Microsoft’s AutoGen, one of the earliest conversational multi-agent systems, has become one of the most popular projects on GitHub with more than 58,700 stars, and is built on this architecture. Dynamic Routing, sometimes called the coordinator model, operates differently. Rather than following a fixed plan, a routing layer receives incoming requests and directs them based on content type, context, or system load, operating more like a real-world operations center than a rigid execution pipeline.
One point deserves explicit attention: multi-agent systems multiply capabilities, but they multiply errors with equal force. An O’Reilly report from early 2026 captured this clearly: most multi-agent systems fail not because of model quality, but because of an engineering tendency to compose agents without accounting for error multiplication. If five agents each fail at a five percent rate, the system compounds those failures unless clear error boundaries are built between them from the start. Begin with the minimum number of agents necessary to solve the problem.
Dynamic routing extends the orchestrator model’s potential. A coordinator agent classifies incoming requests by task type, directing budget or tax queries to a finance domain agent and contractual or correspondence requests to a legal domain agent. This keeps each agent focused, contextually relevant, and productive. Google’s A2A Protocol reached version 1.0 in spring 2026, graduating from an experimental feature to production-ready infrastructure for agent-to-agent handoffs. Anthropic’s MCP, now maintained by the Linux Foundation’s Agentic AI Foundation, provides connectivity with external systems and governs handoffs between agents.
|
Framework |
Best For |
Status |
|
LangGraph |
Production, stateful workflows, audit trails |
Production |
|
CrewAI |
Multi-agent teams with defined roles |
Production |
|
Microsoft AutoGen |
Conversational multi-agent systems |
Mature |
|
OpenAI Agents SDK |
OpenAI-ecosystem production work |
Production |
|
Anthropic MCP |
Standardized tool and agent interoperability |
Emerging Standard |
3. Memory Management and Multi-Session Agents
A demonstration agent is designed to operate in isolation and at speed. A production agent must retrieve results from archives, recall specific information across thousands of documents without loading all of them into context, and maintain enough conversational continuity that users never have to repeat themselves. Multi-session agents preserve context across interactions by combining sensory, short-term, long-term, and procedural memory types.
Each memory type carries its own failure mode. Without proper time-to-live settings, old entries corrupt retrieval. Without contradiction checking, an agent cannot update stale facts, such as a user’s employer or project status, when new information contradicts it. Most production applications require a combination of memory types, yet few engineering teams build a robust retrieval system for long-term memory before deployment.
In April 2026, Mem0 introduced a token-aware algorithm enabling single-pass hierarchical extraction that reduces total tokens to approximately 6,956 per call, down from roughly 26,000 tokens using earlier full-context methods. At the scale of thousands of concurrent conversations, this has a direct impact on the unit economics of production deployments. Mem0’s documentation now covers 21 agent frameworks across Python and TypeScript, an illustration of how fragmented the memory space remains. No single memory solution has become an industry standard. The largest architectural gains have come in temporal reasoning, up 29.6 points, and multi-hop reasoning, up 23.1 points, per Mem0’s State of AI Agent Memory 2026 report, which are precisely the capabilities most vulnerable to stale-memory failures.
4. The Critic Loop and LLM-as-a-Judge Evaluation
An agent that can only move forward is inherently fragile. An error on step three, left unchecked, compounds through every subsequent step and produces output failures that are nearly impossible to trace. The Critic Loop pattern breaks that chain by embedding structured checkpoints. In one common implementation, a separate evaluation agent reviews the working agent’s output against defined criteria before execution proceeds, or the result is delivered to the user.
This pattern has grown significantly more powerful in 2026 as LLM-as-a-Judge methodologies have matured for production scale. The core principle is that one agent evaluates another’s output against measurable attributes: correctness, relevancy, factual accuracy, safety, and stylistic consistency. According to research by Confident AI, LLM judges now agree with human reviewers roughly 85 percent of the time, a rate higher than the 60 percent consistency observed between two human reviewers assessing the same content. Human review is capped at hundreds of evaluations per day; LLM judges operate at production scale and cost between 500 and 5,000 times less than a human annotator.
A study by Eugene Yan on LLM evaluator research found that GPT-4 favors its own outputs over human evaluations at a rate about 10 percent higher than expected, and Claude shows a similar self-preference at roughly 25 percent above baseline. To counteract this, always use a different model from the family for evaluation than the one that has produced the output in assessment.
5. Agents as Tools and Subagent Architecture
Production experience over time has surfaced a consistent lesson about subagent calls: from the parent agent’s perspective, a subagent call must be functionally identical to a tool call. The parent provides a task and receives a result. It should not need to know, and should not be exposed to, the internal steps the subagent took to complete its work, which tools it invoked, how many reasoning steps it required, or what intermediate context it generated.
The most consequential benefit of the agent-as-tool approach is context compression. The Cursor team explained the principle on Latent Space: if a subagent reads eight files and makes 15 tool calls to produce an answer, the parent agent receives a 750-token summary of the output rather than the full trace. This keeps the parent’s context window clean, efficient, and populated only with information relevant to its current reasoning. The performance gain comes from delegation, not parallelism.
Datadog’s State of AI Engineering 2026 report found that 69 percent of all LLM input tokens in production agentic applications were system prompt tokens, the tokens that define available tools and their operating constraints. Designing those tool definitions carefully is not optional: a subtle error in a tool contract can break an entire chain of dependent downstream tools. Anthropic’s Model Context Protocol, donated to the Linux Foundation’s Agentic AI Foundation in early 2026 and subsequently adopted by OpenAI and Microsoft, surpassed 97 million installs by March. The protocol provides the abstraction layer that makes the agent-as-tool pattern viable for composability at scale.
6. The Agentic System Harness and Optimization Layer

Every production system requires infrastructure not for doing the core work, but for sustaining that work reliably at scale. Observability, cost tracking, rate limiting, retry logic, caching, and intelligent model routing are not optional features. They are the structural difference between a promising prototype and a deployable product.
Harrison Chase popularized the term “context engineering” to describe the discipline of building the optimal environment from which an agent draws its operational context. Prompting is what you ask for the model. Context engineering is the practice of constructing the environment in which the model operates and retrieves information. At LangChain’s Interrupt 2026 conference, nearly every practitioner describing production deployments from companies including Lyft, Cisco, Toyota, and LATAM cited LangSmith as a comparable observability tool as essential infrastructure. Routing simple retrieval tasks to smaller, less expensive models rather than defaulting to frontier models for every computation can substantially reduce per-task costs without measurable quality loss.
The primary failure modes in this category include context drift, schema misalignment, state degradation, and a disconnect between the value a model is expected to create and the quality of data provided to it. A model cannot be reliably optimized without first establishing a stable operational harness. Only after a system is consistently delivering clean, structured data can the model’s performance be meaningfully tuned.
“Building AI agents is 10% wow and 90% why is it doing that? We are no longer debating whether agents will work. We are debating how to make them work reliably, at scale, inside real products, with all the messy constraints that come with production.”
— Harrison Chase, Co-Founder and CEO, LangChain
7. Human-in-the-Loop Systems and Approval Gates
Agents built with Human-in-the-Loop (HITL) architecture include deliberate checkpoints at which execution pauses for a human decision before the agent acts with significant or irreversible consequences. The resistance many engineering teams feel toward HITL typically stems from a mischaracterization of what automation means in this context. HITL is frequently treated as a temporary measure, a step to be eventually removed once the agent has earned sufficient trust. That framing is both technically incorrect and commercially costly.
A 2026 analysis by Hypersense Software found that among production deployments at the time of the study, those achieving a meaningful return on investment with the lowest risk profile were not the ones that maximized total automation across all tasks. They were the deployments that applied automation selectively: identifying which tasks warranted full automation, establishing clear escalation procedures for the remainder, and using human feedback within those escalation paths to improve performance iteratively. The architecture of HITL systems spans a spectrum from full human supervision at one end to full autonomy for narrow, low-risk tasks at the other, with graduated configurations between them calibrated to the risk level and confidence of the task being performed.
HITL gates are no longer an optional safety measure for technology organizations. The EU AI Act came into full effect in early 2026, requiring high-risk agentic systems operating in healthcare, credit assessment, legal services, employment decisions, and critical infrastructure to maintain effective human control by August 2026. Security teams have additional motivation: OWASP’s LLM Applications Top 10 for 2026 lists prompt injection as the leading vulnerability, with an 84 percent success rate against agentic systems. The EchoLeak vulnerability in Microsoft 365 Copilot and a critical remote code execution flaw in GitHub Copilot (CVE-2025-53773, CVSS score 9.6) illustrate that any agent connected to external tools is an attack surface. Human review gates remain one of the most effective mechanisms for intercepting harmful outputs before they cause downstream damage.
Production Tip
HITL gates must be designed into the system from the start, not added after the agent is built. Before writing a single line of agent code, establish a documented list of which action categories require human review and approval, developed with input from those who understand the legal and operational consequences for the business.

