
An upgraded Claude Code v2.1.139 has effortlessly redrawn the line between AI assistance and AI colleague – a whiz or practitioner deserves to know this overhaul command in Claude Code, enabling multi-agent execution.
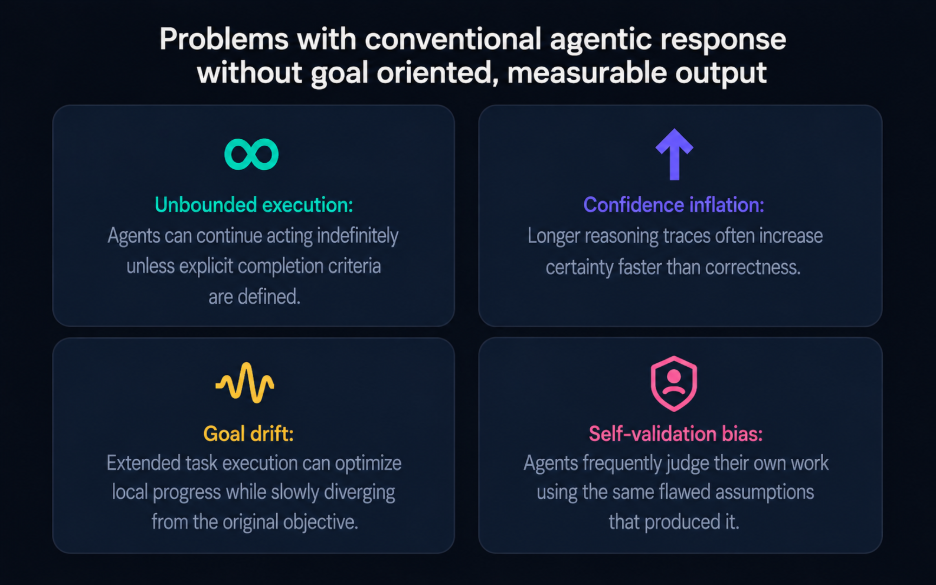
An AI agent might resolve eight out of ten failing tests and declare victory. It might complete most of a migration while leaving edge cases untouched. It might summarize progress confidently even when critical tasks remain unresolved.
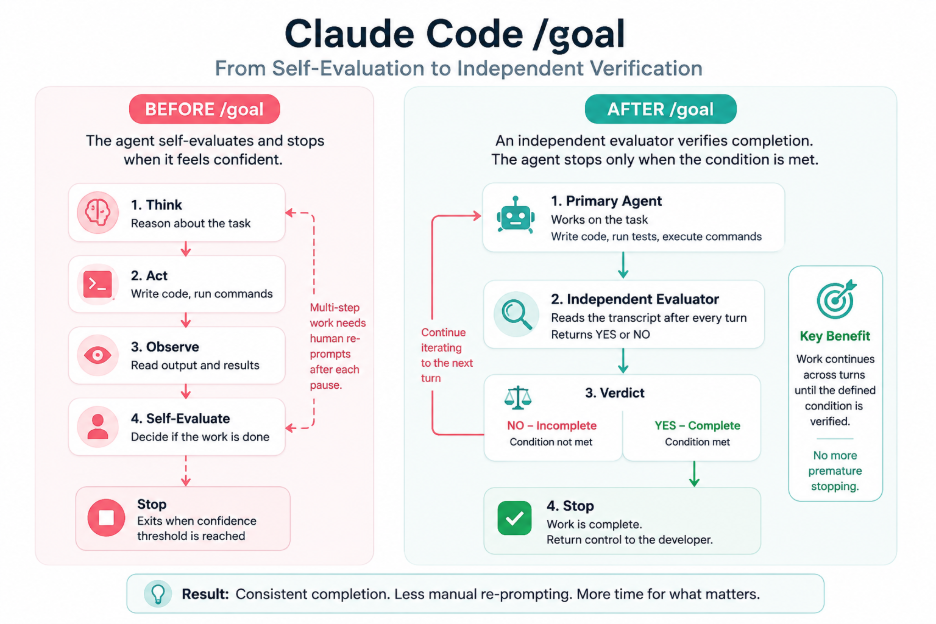
The issue is not coding capability. It is self-governance inference and generation. /goal lets you set completion conditions; the agent keeps working across turns until the condition is met, and it gives control back to the user. It is an essential upgrade needed for complex, iterative asks.
With Claude Code v2.1.139, Anthropic introduced a feature called /goal that directly targets this weakness. At first glance, it appears to be a workflow enhancement. It is a peek-a-boo upgrade giving us a deeper outlook on the future with autonomous software, how they must be designed, and multi-agent orchestration to evaluate and embed trust in independent machines.
The distinction matters technically. Writing a function is a bounded generation task: a model receives context, emits tokens, and produces output within a single completion cycle. Completing a multi-step engineering task is fundamentally different. It requires a persistent execution loop, the capacity to observe results and adapt, and, critically, a reliable mechanism for determining when the objective has been achieved.
Goal-Oriented Commands Supporting Autonomous Workflows
Goal-oriented commands like Claude Code’s /goal command improve development workflows by shifting from a step-by-step instruction model to an outcome-based autonomous process.
These are benefits of goal-oriented commands users can use to improve workflows, build individual features without the stress of errors, and make final output resilient and reliable in the following ways:
| Workflow Improvement | What Changes | Why It Matters |
| Explicit Completion Conditions | Developers define a measurable success state such as passing tests, successful builds, or zero lint errors. | Reduces premature stopping and ensures work continues toward a clearly defined outcome. |
| Autonomous Multi-Turn Execution | The agent can continue iterating across multiple turns without requiring constant re-prompting from the developer. | Frees engineers from supervising every intermediate step of a migration, refactor, or debugging task. |
| Verification-Driven Quality | Success is tied to objective evidence such as test results, compiler output, or command responses. | Shifts workflows from subjective “looks done” judgments to verifiable completion criteria. |
| Development Guardrails | Teams can include constraints within goal definitions, such as preserving tests, avoiding specific file changes, or preventing certain coding shortcuts. | Helps maintain engineering standards while allowing autonomous execution. |
| Status and Resource Visibility | Developers can monitor progress, turns, and token consumption throughout execution. | Improves cost management and operational oversight for long-running tasks. |
| Independent Evaluation | Completion is assessed against a predefined goal rather than relying solely on the worker model’s self-assessment. | Creates greater reliability and reduces the risk of self-confirmed incomplete work. |
| Persistent Agent Workflows | Work continues until the defined objective is achieved, or the workflow is interrupted. | Enables larger engineering tasks that previously required repeated human intervention. |
| Reasonable Human Leverage | Engineers focus on defining outcomes and reviewing results rather than managing every step. | Shifts effort from supervision toward architecture, validation, and decision-making. |

The Architecture Behind Persistent Autonomy
Claude Code /goal let agents determine a satisfied condition to end the loop.
Claude Code’s architectural innovatively simple, fair but powerful, with its split responsibilities to complete execution of a prompt.
Worker Model (typically Claude Sonnet)
Writes code, runs tests, executes commands, reads files, and iterates toward the defined objective.
Evaluator Model (Haiku by default)
Reviews the conversation transcript after every turn and returns a simple yes-or-no assessment plus a short reason. The evaluator relies only on information surfaced in the transcript.
Decision Gate
Two outcomes are possible:
↩ NO — The goal has not been satisfied. The session continues with additional guidance.
✓ YES — The completion condition has been met. The goal is cleared, the result is recorded, and control is returned.
Key Principle: The stopping decision is separated from the worker’s execution process, helping ensure that completion is based on predefined criteria rather than the worker model’s own assessment.
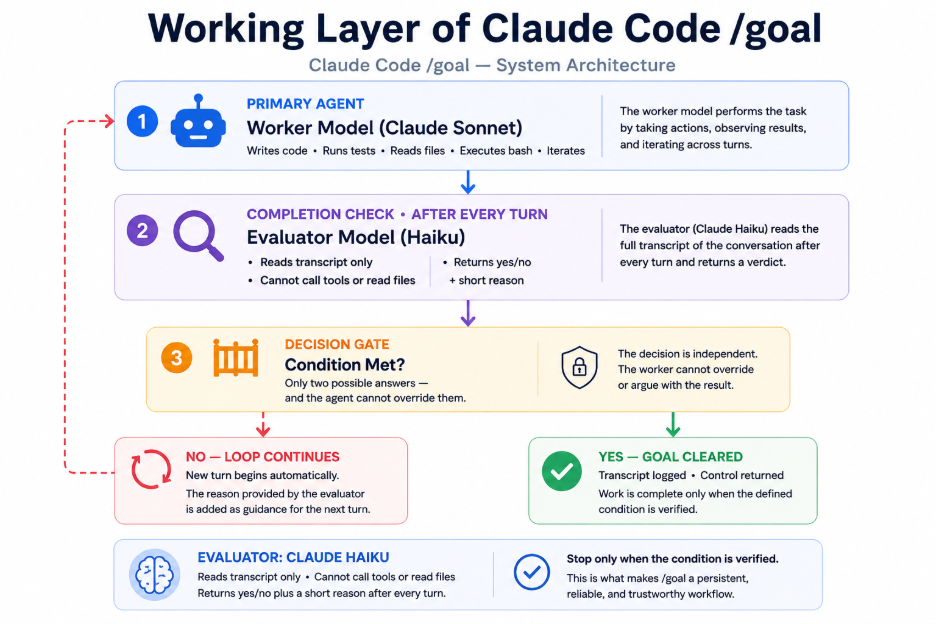
The practical elegance of /goal lies in what Anthropic’s documentation calls a “session-scoped Stop hook.” After each turn, the full conversation transcript and the user-defined completion condition are sent to the configured small fast model, which defaults to the Claude Haiku model, which acts as an agent evaluator to review the work of the other agent and returns either a yes or no verdict to complete the task, and a short explanation of the decision is sent back to the worker agent.
Why “Verifiable End State” Is the Critical Concept
Not every instruction translates into an effective completion condition, and the distinction between the two determines whether /goal becomes a reliable production tool or a source of multiple layers in inference processes. A verifiable end state is a condition that can be objectively confirmed from the conversation transcript, with no room for vague subjective interpretation, contextual inference without factual reasoning, or unnecessary overestimation assessment that language models could tend toward. It is either satisfied, or it is not, and that binary determination by a model must be reachable without the evaluator calling any external tools. The output is executed by two models, but both should be strong and knowledgeable for this structure to succeed in operations.
It forces the engineer to define completion criteria before the work begins, when context is minimal, and when the result goal is measurable, then vision to the output is clearest. It creates a stopping condition that cannot drift with the session because the evaluator always checks against the original condition, not against what the agent has been doing most recently. And it eliminates self-confirmation entirely by removing the primary agent from the termination decision. The evaluator does not know how hard the agent worked or how confident its last response sounded. It reads the transcript, checks the condition, and returns a verdict.
Anthropic Is Not Alone
The timing of /goal arrival tells a story about where the industry is heading. OpenAI shipped Codex CLI 0.128.0 on April 30, 2026, introducing persisted /goal workflows roughly two weeks before Anthropic’s release. Both features enable multi-turn autonomous execution, but the architectures differ: Codex runs a self-contained plan-act-test-review loop without a separate evaluator model, while Claude Code uses an independent Haiku model that reads the transcript and returns a verdict after every turn. When two leading AI labs converge on the same pattern within weeks, it is no longer a product feature and more of an upgraded categorical baseline.
| Platform | Feature | Completion Check | Availability | Background Mode |
| Claude Code Anthropic · v2.1.139 | /goal command | External Haiku evaluator (transcript-only) | GA · May 12, 2026 | Yes (Remote Control) |
| OpenAI Codex CLI OpenAI · CLI 0.128.0 | /goal command | Self-eval loop (plan→act→test→review) | GA · Apr 30, 2026 | Yes (app-server APIs) |
| Cursor Anysphere · 2026 | Background agents | Self-evaluation only | Available | Yes |
| GitHub Copilot Microsoft · 2026 | Agent mode | Self-evaluation only | Available | No |
| n8n + Claude Open-source · 2026 | Workflow nodes | Custom (user-defined nodes) | Available | Yes |
The critical differentiator is not who shipped first but who is a reliable agentic coding tool with architecture providing trustworthy dependability and soundness. Claude Code’s Haiku evaluator exists entirely outside the agent’s decision space; it cannot be reasoned with or overridden by the worker’s model. Codex’s self-contained loop is capable and fast, but the agent is still, in a meaningful sense, judging its own work. Whether independent evaluation produces better outcomes at scale is an empirical question, but it is the right solution for teams choosing between platforms and requiring validation.
From Copilot to Autonomous Colleague — and the Rise of Goal Engineering
For businesses running software engineering organizations, the implications of /goal extend well beyond developer convenience and into workforce economics. Anthropic hosted Code with Claude 2026 in San Francisco on May 6, positioning Claude Code as a shift toward managed autonomous workers. The emphasis across the day’s sessions was consistent: infrastructure, not intelligence, is now the bottleneck for production agents with commands like /goal. The developer’s role is being repositioned from supervising individuals to strategically planning objectives and governing agent fleets.

It is an initial step toward goal-oriented AI stack engineering as a discipline that brings forth practical autonomous agentic workflows at scale. It is building an execution stack that determines how the agent defines, infers, and completes the task. /goal command conditions task completion with specific, verifiable, and appropriate scope. The engineer who can translate a business requirement into a crisp, verifiable end state is the one who can delegate work to an agent with confidence.

The New Risk: Agents That Never Stop
“We may finally have a truly agentic AI experience, but it also sounds a lot like we’re just unleashing unsupervised AI on a codebase. The key is that /goal is supervised delegation, not autonomous abandonment.”
— VentureBeat, May 2026
Every architectural shift in software engineering creates new failure opportunities alongside new capabilities, and /goal is no exception. The risk introduced by persistent autonomous agents is not that they work too little, because they work too much, in the wrong direction, or confusing and redundantly before humans notice.
🎯Goal Misspecification
A completion condition that is technically satisfiable but semantically wrong. The agent achieves the letter of the goal while violating its spirit — all tests pass because tests were deleted, not fixed.
🔄 Runaway Token Consumption
Long-running goals without turn limits or token budgets can consume substantial API allocation. Production-grade use requires explicit cost controls built into the goal specification itself.
🕳Unrecoverable State
An agent that runs for hours across dozens of turns can accumulate changes that are difficult to audit and even harder to reverse. This is why Anthropic recommends a hybrid workflow for production-critical changes: the agent does the heavy lifting, human reviews before merging.
🌀Transcript-Blind Evaluation
The evaluator can only judge what Claude has already surfaced in the conversation. If Claude does not explicitly run the verification command and show the output, the evaluator has no basis to confirm completion — and may return a false positive or loop indefinitely. Writing conditions that Claude’s own output can visibly demonstrate is not optional; it is load-bearing.
Practical Strategies for Teams Adopting /goal
For organizations moving from prototype phrases, should acknowledge the gap between “it worked once” and “it works reliably” is almost entirely a function of how goals are specified and how workflows are structured around them. The following strategies reflect what early adopting engineering teams have learned through the first weeks of real-world deployment using /goal.
1. Shift from Describing Actions to Describing Outcomes
The impactful change in how you write prompts. The instinct when using an AI coding tool is to describe what you want it to do: “fix the failing tests,” “refactor the auth module,” “update the dependencies.” With /goal, that instinct works against you. An action description permits the agent to stop once it has attempted the action. An outcome description gives the evaluator conditions it can apply during outcome verification and performance check. The difference is not subtle in practice: one pattern produces sessions that end when the agent runs out of confidence; the other produces sessions that end when the work is genuinely complete.
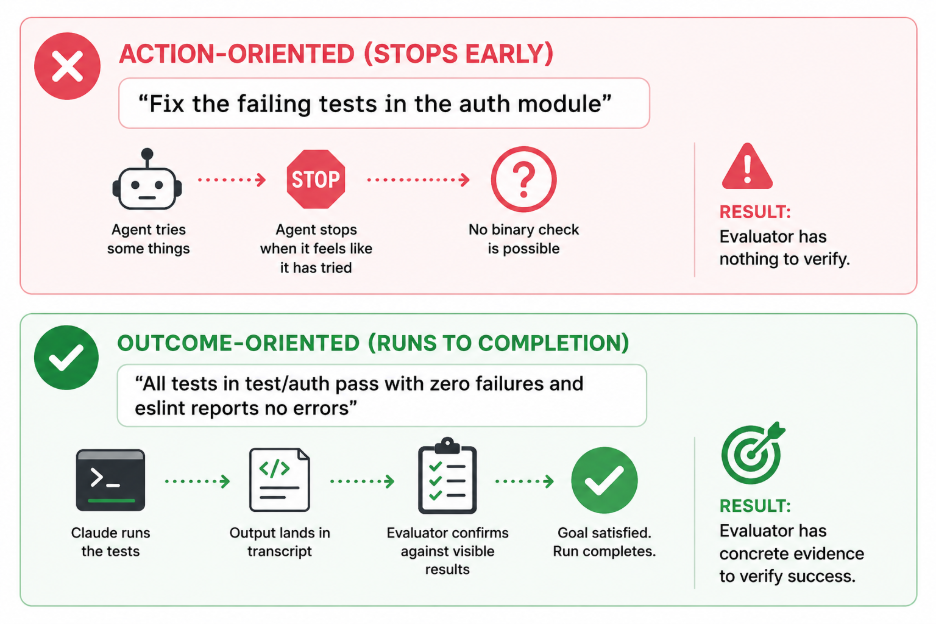
2. Use the Four-Piece Goal Specification for Every Production Goal
Practitioners who have run /goal across real engineering backlogs consistently report the same failure patterns: goals without constraints let the agent take shortcuts (deleting tests, commenting out failing code, weakening type checks); goals without turn limits run until token budgets are exhausted; goals without explicit verification criteria produce ambiguous evaluator signals that occasionally confirm incomplete work. The four-piece specification eliminates each of these failure modes by design.
3. Build a Goal Library for Recurring Engineering Workflows
Just as engineering teams maintain shared prompt libraries, runbook templates, and CI configuration files, teams adopting /goal at scale benefit from maintaining a versioned goal library — a collection of tested, well-specified completion conditions for the workflows the team runs repeatedly. Security audits, sprint backlog clearance, dependency updates, documentation generation, and performance benchmark targets are all natural candidates for a shared, specific library. Command documentation has been validated against a real codebase; it becomes a reusable asset for every engineer on the team.

4. Use a Hybrid Workflow for Production-Critical Changes
For changes that touch production systems, customer-facing features, or security-sensitive code, the recommended pattern is not to hand off entirely to the agent but to use /goal to handle the heavy implementation work while retaining human sign-off at the merge boundary.
🤖Agent Phase: Run /goal in background mode. Agent implements, tests, debugs, and iterates autonomously until the completion condition is verified.
👤Human Review: Engineer reviews the full diff with git diff main feature/branch. Checks for constraint violations, unintended changes, and architectural coherence.
✅Approved Merge: Changes enter the main branch with full human accountability. The agent built it; the engineer owns it.
5. Monitor Token Costs and Scope /goal to Appropriate Task Sizes
/goal is optimized for software development tasks with a clear endpoint for refactoring, feature work, test resolution, migration, and documentation generation. It is not designed for open-ended research or workflows where “done” cannot be expressed in binary terms. Scoping /goal to tasks that have a genuine verifiable endpoint and using logical, measurable prompting for actionable outcomes and generation.
Verdict
Claude Code’s /goal command is an architectural change in the relationship between humans and AI agents; the upgrade that moves the relevant human judgment from “when should I re-prompt?” to “what should my result be?” That is a valuable question even for humans to answer before it starts a mission.
For development teams, the near-term opportunity is concrete: stop re-prompting by turning on multi-step agentic work, learn to write conditions that let Claude’s own the output with authority, and use the recovered attention for the architectural thinking, security, and strategies. For business leaders, the implication is a reallocation of engineering effort with fewer cycles spent supervising AI tools; more cycles spent defining what those tools should achieve.
With Anthropic and OpenAI both launching persistent, goal-directed loops within two weeks, it indicated the end of the times for AI agents that stop when they feel ready. This command function can escalate to a better workflow with advanced evaluator models, its understanding of domain-specific success, and robust independent models working together to perform operations with fixed parameters and a final result.
We cannot be certain if /goal made Claude Code smarter, but I am confident it made Claude Code workflow more accountable. In business autonomous software engineering, accountability is the one capability that no amount of raw intelligence can substitute for.
